Mục lục [Ẩn]
- 1. Data Mining là gì?
- 2. Data Mining giải quyết vấn đề gì cho doanh nghiệp
- 3. Các kỹ thuật được sử dụng trong Data Mining
- 3.1. Kỹ thuật phân tích phân loại (Classification Analysis)
- 3.2. Kỹ thuật học luật kết hợp (Association Rule Learning)
- 3.3. Kỹ thuật phát hiện bất thường (Anomaly Detection)
- 3.4. Kỹ thuật phân tích cụm (Clustering Analysis)
- 3.5. Kỹ thuật phân tích hồi quy (Regression Analysis)
- 3.6. Kỹ thuật dự báo (Prediction)
- 4. Quy trình khai phá dữ liệu
- Bước 1: Làm sạch dữ liệu (Data Cleaning)
- Bước 2: Tích hợp dữ liệu (Data Integration)
- Bước 3: Lựa chọn dữ liệu (Data Selection)
- Bước 4: Chuyển đổi dữ liệu (Data Transformation)
- Bước 5: Khai phá dữ liệu (Data Mining)
- Bước 6: Đánh giá mẫu (Pattern Evaluation)
- Bước 7: Trình bày thông tin (Information Presentation)
- 5. Ứng dụng Data Mining trong kinh doanh (case theo phòng ban)
- 5.1. Data Mining trong Marketing
- 5.2. Data Mining trong Sales
- 5.3. Data Mining trong Chăm sóc khách hàng (CSKH)
- 5.4. Data Mining trong vận hành – tồn kho – chuỗi cung ứng
- 5.5. Data Mining trong tài chính – rủi ro
- 6. Những sai lầm khiến Data Mining thất bại
Dữ liệu trong doanh nghiệp ngày càng nhiều: từ CRM, website, quảng cáo đến bán hàng và chăm sóc khách. Nhưng thực tế, có dữ liệu chưa đồng nghĩa ra quyết định tốt - vì dữ liệu thường chỉ nằm ở dạng lưu trữ, chưa được khai thác thành insight phục vụ quản trị. Data Mining (khai phá dữ liệu) giúp doanh nghiệp phát hiện mẫu hành vi, xu hướng và mối liên hệ ẩn để trả lời các câu hỏi quản trị quan trọng: ai là khách hàng tốt, kênh nào hiệu quả, nhu cầu sắp biến động ra sao và rủi ro đang nằm ở đâu. Cùng HBR tìm hiểu Data Mining và cách ứng dụng để xây năng lực quản trị theo data.
Điểm qua những nội dung chính của bài:
- Data Mining giải quyết 5 vấn đề cho doanh nghiệp: tìm khách tiềm năng, dự báo nhu cầu, tối ưu marketing, phát hiện rủi ro/gian lận, tăng bán chéo – bán thêm.
- Các kỹ thuật được sử dụng trong Data Mining: Phân loại, luật kết hợp, phát hiện bất thường, phân cụm, hồi quy và dự báo.
- Quy trình khai phá dữ liệu: Làm sạch → tích hợp → lựa chọn → chuyển đổi → khai phá → đánh giá → trình bày kết quả.
Ứng dụng Data Mining trong kinh doanh: Marketing (phân khúc, remarketing), Sales (lead scoring, dự đoán chốt), CSKH (dự đoán churn), Vận hành (dự báo nhu cầu, tồn kho), Tài chính (cảnh báo bất thường).- Những sai lầm khiến Data Mining thất bại: Thiếu bài toán rõ ràng, dữ liệu không chuẩn, kỳ vọng làm một lần là xong, không có KPI, không tích hợp vào vận hành
1. Data Mining là gì?
Data Mining (khai phá dữ liệu) là quá trình phân loại và tổ chức các tập dữ liệu lớn nhằm xác định các mẫu (patterns) và thiết lập các mối liên hệ (relationships) để hỗ trợ giải quyết vấn đề thông qua phân tích dữ liệu. Nhờ các mô hình và công cụ khai phá dữ liệu, doanh nghiệp có thể dự đoán xu hướng trong tương lai dựa trên hành vi và biến động của dữ liệu hiện có.

Quá trình khai phá dữ liệu tương đối phức tạp, đòi hỏi sự kết hợp giữa kho dữ liệu chuyên sâu (data warehouse) và các công nghệ tính toán hiện đại. Bên cạnh việc trích xuất thông tin, Data Mining còn bao gồm nhiều hoạt động quan trọng khác như chuyển đổi dữ liệu (data transformation), làm sạch dữ liệu (data cleaning), tích hợp dữ liệu (data integration) và phân tích các mẫu dữ liệu nhằm tạo ra insight có giá trị.
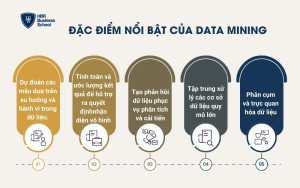
Trong Data Mining, có nhiều tham số và kỹ thuật trọng yếu, tiêu biểu như quy tắc kết hợp (association rules), phân loại (classification), phân cụm (clustering) và dự báo (forecasting). Một số đặc điểm nổi bật của Data Mining bao gồm:
- Dự đoán các mẫu dựa trên xu hướng và hành vi trong dữ liệu.
- Tính toán và ước lượng kết quả để hỗ trợ ra quyết định.
- Tạo phản hồi dữ liệu phục vụ phân tích và cải tiến liên tục.
- Tập trung xử lý các cơ sở dữ liệu quy mô lớn, đa nguồn.
- Phân cụm và trực quan hóa dữ liệu, giúp nhận diện nhóm và cấu trúc dữ liệu rõ ràng hơn.
2. Data Mining giải quyết vấn đề gì cho doanh nghiệp
Trong bối cảnh doanh nghiệp ngày càng có nhiều dữ liệu từ CRM, website, quảng cáo, bán hàng và chăm sóc khách hàng, thách thức lớn nhất không nằm ở việc “có dữ liệu”, mà là biến dữ liệu thành insight và quyết định đúng. Data Mining (khai phá dữ liệu) giúp doanh nghiệp phát hiện các mẫu ẩn, xu hướng và mối liên hệ trong dữ liệu, từ đó hỗ trợ giải quyết các bài toán trọng tâm liên quan đến doanh thu – chi phí – rủi ro.
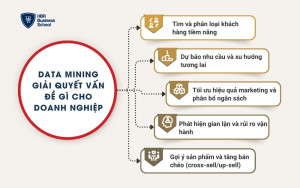
Cụ thể, Data Mining thường được ứng dụng để giải quyết 5 nhóm vấn đề chính:
- Tìm và phân loại khách hàng tiềm năng: Data Mining giúp xác định nhóm khách có khả năng mua cao dựa trên hành vi và lịch sử tương tác (lead scoring). Nhờ đó, doanh nghiệp tối ưu hiệu suất sale và marketing, tập trung nguồn lực vào nhóm khách “đúng” thay vì chăm sóc dàn trải.
- Dự báo nhu cầu và xu hướng tương lai: Thông qua phân tích dữ liệu lịch sử, Data Mining hỗ trợ dự đoán doanh số, nhu cầu thị trường, vòng đời mua hàng và biến động theo mùa. Đây là nền tảng để doanh nghiệp lập kế hoạch sản xuất – tồn kho – tài chính chính xác hơn.
- Tối ưu hiệu quả marketing và phân bổ ngân sách: Data Mining giúp doanh nghiệp hiểu rõ kênh nào mang lại khách chất lượng, nội dung nào tạo chuyển đổi, nhóm khách nào có giá trị cao (LTV). Từ đó, doanh nghiệp có thể giảm lãng phí quảng cáo, cải thiện ROI và tăng doanh thu trên cùng ngân sách.
- Phát hiện gian lận và rủi ro vận hành Khai phá dữ liệu cho phép nhận diện hành vi bất thường trong đơn hàng, hoàn tiền, sử dụng ưu đãi hoặc sai lệch vận hành. Nhờ vậy doanh nghiệp giảm thất thoát và kiểm soát rủi ro tốt hơn.
- Gợi ý sản phẩm và tăng bán chéo (cross-sell/up-sell): Bằng cách phân tích mối liên hệ giữa các sản phẩm và hành vi mua, Data Mining giúp gợi ý sản phẩm phù hợp, tăng giá trị đơn hàng và cải thiện tỷ lệ mua lặp lại.
Data Mining không chỉ là phân tích dữ liệu, mà là công cụ giúp doanh nghiệp trả lời nhanh các câu hỏi quan trọng: Ai là khách hàng tốt? Xu hướng nào sắp xảy ra? Làm thế nào để tối ưu marketing và vận hành để tăng lợi nhuận bền vững?
3. Các kỹ thuật được sử dụng trong Data Mining
Các kỹ thuật khai phá dữ liệu được sử dụng nhằm phân tích, trích xuất và tổ chức thông tin từ dữ liệu một cách hiệu quả. Tùy theo mục tiêu khai thác, Data Mining có thể áp dụng nhiều phương pháp khác nhau, từ đơn giản đến phức tạp. Dưới đây là một số kỹ thuật quan trọng và phổ biến:
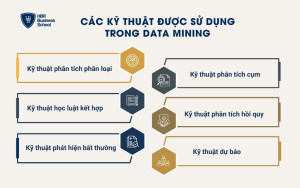
- Kỹ thuật phân tích phân loại (Classification Analysis)
- Kỹ thuật học luật kết hợp (Association Rule Learning)
- Kỹ thuật phát hiện bất thường (Anomaly Detection)
- Kỹ thuật phân tích cụm (Clustering Analysis)
- Kỹ thuật phân tích hồi quy (Regression Analysis)
- Kỹ thuật dự báo (Prediction)
3.1. Kỹ thuật phân tích phân loại (Classification Analysis)
Phân loại là một trong những kỹ thuật Data Mining được ứng dụng rộng rãi nhất. Phương pháp này cho phép gán một đối tượng vào các nhóm (lớp) đã được định nghĩa sẵn dựa trên những thuộc tính cụ thể. Kỹ thuật phân loại thường được sử dụng để trích xuất thông tin quan trọng, phục vụ cho hoạt động dự đoán hoặc phân tích xu hướng trong tương lai.
Ví dụ:
- Gmail áp dụng thuật toán phân loại để xác định email thuộc nhóm hợp lệ hay spam.
- Trong quảng cáo – tiếp thị, doanh nghiệp có thể phân loại khách hàng theo độ tuổi, sở thích hoặc hành vi mua sắm, từ đó tối ưu chiến lược tiếp cận và nâng cao hiệu quả truyền thông.
3.2. Kỹ thuật học luật kết hợp (Association Rule Learning)
Association Rule Learning tập trung vào việc tìm kiếm mối liên hệ giữa các biến trong cơ sở dữ liệu, nhằm phát hiện những mẫu ẩn tiềm năng. Đây là kỹ thuật đặc biệt phù hợp trong lĩnh vực bán lẻ, giúp doanh nghiệp phân tích và dự đoán hành vi mua sắm của khách hàng.
Ví dụ: Thông qua phân tích giỏ hàng, các sàn thương mại điện tử có thể nhận ra xu hướng khách thường mua cushion cùng kem che khuyết điểm. Dựa trên kết quả này, doanh nghiệp có thể:
- Thiết kế chương trình khuyến mãi phù hợp, hoặc
- Đề xuất sản phẩm kem che khuyết điểm bán chạy khi khách thêm cushion vào giỏ hàng nhằm kích thích mua hàng.
Ngoài lĩnh vực bán lẻ, kỹ thuật luật kết hợp còn được ứng dụng trong công nghệ để hỗ trợ phát triển các thuật toán trong Machine Learning.
3.3. Kỹ thuật phát hiện bất thường (Anomaly Detection)
Kỹ thuật phát hiện bất thường trong Data Mining tập trung vào việc xác định các điểm dữ liệu khác biệt hoặc ngoại lệ trong tập dữ liệu. Đây là công cụ hữu ích để phát hiện những vấn đề tiềm ẩn như gian lận tài chính, xâm nhập hệ thống hoặc các biến động bất thường trong hoạt động kinh doanh.
Ví dụ:
- Trong sản xuất, kỹ thuật này giúp giám sát dây chuyền tự động và cảnh báo cho người vận hành khi xuất hiện tín hiệu bất thường.
- Trong lĩnh vực bảo mật, nó được dùng để nhận diện sớm các dấu hiệu tấn công mạng, từ đó hỗ trợ ngăn chặn rủi ro kịp thời.
3.4. Kỹ thuật phân tích cụm (Clustering Analysis)
Phân cụm là phương pháp khai phá dữ liệu nhằm nhóm các đối tượng tương đồng thành từng cụm, trong đó các đối tượng trong cùng một cụm có chung đặc điểm. Kỹ thuật này hỗ trợ phân tích dữ liệu hiệu quả hơn và giúp doanh nghiệp ra quyết định dựa trên phân nhóm rõ ràng.
Ví dụ:
Trong marketing, phân cụm thường được sử dụng để phân khúc khách hàng theo hành vi hoặc nhu cầu, giúp doanh nghiệp hiểu sâu hơn từng nhóm khách hàng. Ngoài ra, kỹ thuật này cũng được ứng dụng trong các ngành bán lẻ và tài chính – ngân hàng nhằm xây dựng hồ sơ khách hàng và thiết kế chiến lược chăm sóc phù hợp.
3.5. Kỹ thuật phân tích hồi quy (Regression Analysis)
Hồi quy là một kỹ thuật quan trọng dùng để xác định và phân tích mối quan hệ giữa các biến, đặc biệt phù hợp trong việc dự đoán các giá trị liên tục như doanh thu, chi phí hoặc nhu cầu trong tương lai.
Ví dụ: Một doanh nghiệp sản xuất có thể sử dụng hồi quy để dự đoán doanh thu và lợi nhuận dựa trên sản lượng bán ra. Nhờ đó, doanh nghiệp có thể kiểm soát tốt hơn chi phí đầu tư, tối ưu kế hoạch kinh doanh và xây dựng chiến lược dài hạn hiệu quả.
3.6. Kỹ thuật dự báo (Prediction)
Dự báo là một kỹ thuật khai phá dữ liệu quan trọng, giúp phát hiện mối quan hệ giữa biến độc lập và biến phụ thuộc để đưa ra dự đoán trong tương lai.
Ví dụ: Trong kinh doanh, doanh nghiệp có thể dự báo doanh số dựa trên xu hướng mua sắm hiện tại của khách hàng. Điều này không chỉ giúp tối ưu phân bổ nguồn lực mà còn nâng cao khả năng đáp ứng thị trường, đặc biệt trong các giai đoạn cao điểm hoặc biến động nhu cầu.
4. Quy trình khai phá dữ liệu
Quá trình Data Mining (khai phá dữ liệu) không chỉ đơn thuần là “đào dữ liệu để lấy insight”, mà là một chuỗi bước có tính hệ thống nhằm đảm bảo dữ liệu đầu vào đủ chất lượng, phương pháp phân tích phù hợp và kết quả đầu ra có thể sử dụng được trong thực tế. Dưới đây là các bước quan trọng thường gặp trong quy trình Data Mining:
- Bước 1: Làm sạch dữ liệu (Data Cleaning)
- Bước 2: Tích hợp dữ liệu (Data Integration)
- Bước 3: Lựa chọn dữ liệu (Data Selection)
- Bước 4: Chuyển đổi dữ liệu (Data Transformation)
- Bước 5: Khai phá dữ liệu (Data Mining)
- Bước 6: Đánh giá mẫu (Pattern Evaluation)
- Bước 7: Trình bày thông tin (Information Presentation)

Bước 1: Làm sạch dữ liệu (Data Cleaning)
Đây là bước nền tảng và có ảnh hưởng lớn đến toàn bộ kết quả khai phá dữ liệu. Ở giai đoạn này, dữ liệu sẽ được xử lý để loại bỏ các yếu tố gây nhiễu như:
- Dữ liệu bị thiếu hoặc trống (missing values)
- Dữ liệu trùng lặp (duplicates)
- Sai định dạng hoặc sai kiểu dữ liệu (format/type errors)
- Các giá trị bất thường hoặc ngoại lệ (outliers)
Mục tiêu của bước làm sạch là đảm bảo dữ liệu “sạch”, nhất quán và đủ độ tin cậy để đưa vào các bước phân tích tiếp theo.
Bước 2: Tích hợp dữ liệu (Data Integration)
Trong thực tế, dữ liệu của doanh nghiệp thường nằm rải rác ở nhiều nguồn khác nhau như CRM, hệ thống bán hàng, website, nền tảng quảng cáo, phần mềm kế toán, file Excel… Vì vậy, ở bước này, dữ liệu từ các nguồn sẽ được kết hợp lại thành một tập dữ liệu thống nhất, giúp phân tích được toàn cảnh thay vì nhìn từng mảnh rời rạc.
Tích hợp dữ liệu giúp doanh nghiệp tránh tình trạng dữ liệu “mỗi nơi một kiểu” và tạo tiền đề để phát hiện các mối liên hệ sâu hơn trong hành vi khách hàng hoặc vận hành.
Bước 3: Lựa chọn dữ liệu (Data Selection)
Không phải dữ liệu nào cũng cần thiết cho mục tiêu khai phá. Ở bước này, dữ liệu phù hợp sẽ được trích xuất và lựa chọn từ cơ sở dữ liệu dựa trên bài toán đặt ra.
Ví dụ: nếu mục tiêu là dự đoán churn (khách rời bỏ), dữ liệu cần ưu tiên có thể là lịch sử mua, tần suất tương tác, phản hồi khiếu nại… thay vì toàn bộ dữ liệu hệ thống.
Việc lựa chọn đúng dữ liệu giúp giảm khối lượng xử lý và tăng độ chính xác của phân tích.
Bước 4: Chuyển đổi dữ liệu (Data Transformation)
Sau khi lựa chọn, dữ liệu sẽ được chuyển đổi để phù hợp với việc phân tích và khai phá mẫu. Các hoạt động thường bao gồm:
- Chuẩn hóa dữ liệu (normalization/standardization)
- Gom nhóm, tóm tắt (summarization)
- Tạo biến mới (feature engineering)
- Tổng hợp dữ liệu theo thời gian/khu vực/nhóm khách hàng (aggregation)
Mục tiêu của bước này là giúp dữ liệu “đúng định dạng” và “đúng cấu trúc” để thuật toán có thể xử lý hiệu quả.
Bước 5: Khai phá dữ liệu (Data Mining)
Đây là bước cốt lõi của toàn bộ quy trình. Ở giai đoạn này, các kỹ thuật khai phá dữ liệu sẽ được áp dụng để trích xuất thông tin hữu ích và phát hiện:
- Mẫu hành vi (patterns)
- Xu hướng (trends)
- Mối tương quan (correlations)
- Các điểm bất thường (anomalies)
Tùy mục tiêu, doanh nghiệp có thể sử dụng các kỹ thuật như phân loại, phân cụm, luật kết hợp, hồi quy hoặc dự báo.
Bước 6: Đánh giá mẫu (Pattern Evaluation)
Sau khi phát hiện các mẫu hoặc kết quả khai phá, bước tiếp theo là đánh giá mức độ chính xác và ý nghĩa của chúng. Không phải mẫu nào tìm thấy cũng có giá trị ứng dụng; một số mẫu có thể chỉ là trùng hợp hoặc không đủ mạnh để ra quyết định.
Ở bước này, doanh nghiệp thường kiểm tra:
- Mẫu có đáng tin cậy không
- Mẫu có tạo tác động đến KPI kinh doanh không
- Mẫu có thể triển khai thành hành động cụ thể không
Đây là bước giúp doanh nghiệp lọc lại insight thật sự có giá trị.
Bước 7: Trình bày thông tin (Information Presentation)
Cuối cùng, kết quả Data Mining sẽ được trình bày theo cách dễ hiểu và dễ sử dụng cho người ra quyết định. Thông tin có thể được thể hiện dưới nhiều dạng như:
- Bảng dữ liệu (tables)
- Biểu đồ trực quan (charts)
- Cây quyết định (decision trees)
- Ma trận (matrices)
- Dashboard báo cáo
Mục tiêu của bước này là giúp người dùng không chuyên về dữ liệu cũng có thể hiểu được insight và đưa ra hành động phù hợp.
5. Ứng dụng Data Mining trong kinh doanh (case theo phòng ban)
Trong doanh nghiệp, dữ liệu thường nằm rải rác ở CRM, website, quảng cáo, bán hàng, kho vận và chăm sóc khách. Data Mining giúp khai thác các mẫu ẩn và mối liên hệ trong dữ liệu để doanh nghiệp ra quyết định chính xác hơn, đặc biệt trong 3 mục tiêu: tăng doanh thu – giảm chi phí – kiểm soát rủi ro.
Dưới đây là các ứng dụng phổ biến của Data Mining theo từng phòng ban:
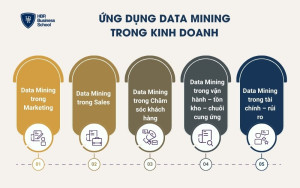
- Data Mining trong Marketing
- Data Mining trong Sales
- Data Mining trong Chăm sóc khách hàng (CSKH)
- Data Mining trong vận hành – tồn kho – chuỗi cung ứng
- Data Mining trong tài chính – rủi ro
5.1. Data Mining trong Marketing
Mục tiêu: hiểu khách hàng sâu hơn để tối ưu chuyển đổi và ngân sách.
Ứng dụng chính:
- Phân khúc khách hàng (Segmentation): chia khách theo hành vi mua, mức chi tiêu, nhu cầu.
- Dự đoán hành vi mua (Purchase Prediction): nhận diện nhóm có khả năng mua cao để tối ưu remarketing.
- Tối ưu kênh và nội dung: tìm ra kênh nào mang về khách chất lượng, nội dung nào tạo chuyển đổi tốt.
Ví dụ nhanh: Khách xem trang giá 2–3 lần + bỏ giỏ + quay lại trong 7 ngày → được xếp vào nhóm “nóng” để ưu tiên quảng cáo hoặc gửi ưu đãi.
Giá trị: tăng conversion, giảm CAC, tăng ROI quảng cáo.
5.2. Data Mining trong Sales
Mục tiêu: tăng tỷ lệ chốt và nâng hiệu suất đội sales.
Ứng dụng chính:
- Lead Scoring: chấm điểm lead dựa trên hành vi và lịch sử tương tác.
- Dự đoán khả năng chốt: phân tích dữ liệu khách đã mua trước đó để dự báo xác suất chốt.
- Gợi ý thời điểm follow-up: xác định khung giờ khách hay phản hồi/chốt cao nhất.
Ví dụ nhanh: Lead đến từ landing page A có tỷ lệ chốt cao hơn 30% so với page B → sales ưu tiên xử lý nhóm lead từ A trước.
Giá trị: tăng tỷ lệ chốt, giảm thời gian chăm sóc dàn trải, tăng năng suất sale.
5.3. Data Mining trong Chăm sóc khách hàng (CSKH)
Mục tiêu: giữ chân khách, tăng mua lại, giảm khiếu nại.
Ứng dụng chính:
- Dự đoán churn (khách rời bỏ): phát hiện sớm khách có dấu hiệu ngừng mua.
- Phân loại phản hồi/khiếu nại: nhóm các phản hồi theo chủ đề (giao hàng, chất lượng, giá, tư vấn…).
- Gợi ý chăm sóc phù hợp: cá nhân hóa kịch bản chăm sóc theo từng nhóm khách.
Ví dụ nhanh: Khách từng mua đều 2 tháng/lần nhưng 60 ngày chưa quay lại → hệ thống cảnh báo để gửi ưu đãi hoặc chăm sóc sớm.
Giá trị: tăng retention, tăng tỷ lệ mua lại, nâng trải nghiệm khách hàng.
5.4. Data Mining trong vận hành – tồn kho – chuỗi cung ứng
Mục tiêu: tối ưu dòng tiền và giảm sai sót trong vận hành.
Ứng dụng chính:
- Dự báo nhu cầu (Demand Forecasting): dự đoán sản phẩm nào sắp bán mạnh theo mùa/chiến dịch.
- Tối ưu tồn kho: tránh thừa hàng hoặc thiếu hàng.
- Phát hiện bất thường trong vận hành: nhận diện đơn hàng, chi phí, quy trình có dấu hiệu sai lệch.
Ví dụ nhanh: Dữ liệu cho thấy mỗi dịp lễ nhu cầu tăng 40% → doanh nghiệp chủ động tăng tồn kho trước 2–3 tuần.
Giá trị: giảm tồn kho, tránh đọng vốn, giảm thất thoát và sai sót.
5.5. Data Mining trong tài chính – rủi ro
Mục tiêu: phát hiện gian lận và quản trị rủi ro sớm.
Ứng dụng chính:
- Anomaly Detection: nhận diện hành vi bất thường trong thanh toán, hoàn tiền, đơn hàng.
- Dự báo rủi ro: phân tích biến động dữ liệu để dự đoán vấn đề tài chính hoặc vận hành.
Ví dụ nhanh: Một tài khoản đặt nhiều đơn trong thời gian ngắn, trùng IP/số điện thoại, dùng voucher liên tục → hệ thống gắn cờ rủi ro để kiểm tra.
Giá trị: giảm thất thoát, tăng an toàn vận hành, kiểm soát rủi ro tốt hơn.
6. Những sai lầm khiến Data Mining thất bại
Nhiều doanh nghiệp bắt đầu triển khai Data Mining với kỳ vọng “có dữ liệu là sẽ ra insight”, nhưng thực tế lại rơi vào tình trạng: phân tích rất nhiều, báo cáo rất đẹp, nhưng kết quả kinh doanh không thay đổi. Nguyên nhân thường không nằm ở công nghệ, mà nằm ở cách doanh nghiệp triển khai sai ngay từ tư duy và quy trình.
Dưới đây là 4 sai lầm phổ biến nhất khiến Data Mining không tạo ra giá trị thực:
- Làm Data Mining nhưng không có bài toán kinh doanh rõ ràng
- Dữ liệu rời rạc, không chuẩn hóa
- Kỳ vọng “làm 1 lần ra phép màu”
- Không tích hợp vào quy trình vận hành → insight chỉ để… đọc
1 - Làm Data Mining nhưng không có bài toán kinh doanh rõ ràng
Đây là lỗi phổ biến nhất. Doanh nghiệp “làm data mining cho có”, bắt đầu từ việc thu thập dữ liệu, dựng dashboard, chạy mô hình… nhưng lại không trả lời được câu hỏi: mình làm để giải quyết vấn đề gì?
Một dự án Data Mining hiệu quả luôn phải xuất phát từ bài toán cụ thể như:
- Tăng tỷ lệ chốt ở bước tư vấn
- Giảm chi phí quảng cáo nhưng vẫn giữ doanh thu
- Dự báo nhu cầu để giảm tồn kho
- Phát hiện gian lận/đơn bất thường
Nếu không có bài toán rõ, dự án sẽ rơi vào trạng thái “đào dữ liệu không mục tiêu”, dẫn đến insight lan man và không thể hành động.
Hệ quả: làm nhiều nhưng không ra quyết định, tốn thời gian và chi phí, đội ngũ mất niềm tin vào dữ liệu.
2 - Dữ liệu rời rạc, không chuẩn hóa
SMEs thường có dữ liệu nằm ở nhiều nơi: Excel, CRM, Zalo, Facebook, sàn TMĐT, phần mềm kế toán… nhưng không có chuẩn chung về:
- Định dạng dữ liệu
- Tên trường dữ liệu
- Cách nhập dữ liệu
- Cách đo lường
Thậm chí cùng một khách hàng có thể tồn tại ở 3–4 hệ thống khác nhau với thông tin không đồng nhất. Khi dữ liệu đầu vào sai hoặc thiếu, kết quả khai phá sẽ không đáng tin, mô hình dự đoán cũng lệch.
Hệ quả: “garbage in, garbage out” – dữ liệu rác thì insight cũng rác; doanh nghiệp không dám dùng kết quả để ra quyết định.
3 - Kỳ vọng “làm 1 lần ra phép màu”
Nhiều doanh nghiệp nghĩ Data Mining giống như một dự án “làm xong là chạy mãi”. Nhưng thực tế, dữ liệu và hành vi khách hàng thay đổi liên tục. Một mô hình phân tích hoặc dự báo chỉ đúng trong một giai đoạn nhất định, sau đó cần cập nhật và tối ưu.
Data Mining hiệu quả là một quá trình liên tục:
- Phân tích → thử nghiệm → đo → điều chỉnh → cải tiến
Hệ quả: triển khai một lần rồi bỏ, mô hình nhanh chóng lỗi thời, doanh nghiệp kết luận “Data Mining không hiệu quả” dù vấn đề là do cách vận hành.
4 - Không tích hợp vào quy trình vận hành → insight chỉ để… đọc
Đây là điểm khiến nhiều doanh nghiệp “có insight nhưng không ra tiền”. Một insight chỉ thực sự có giá trị khi nó được biến thành hành động và trở thành một phần của quy trình:
- Marketing dùng insight để thay đổi target, content, ngân sách
- Sales dùng lead scoring để ưu tiên gọi đúng khách
- CSKH dùng cảnh báo churn để giữ khách sớm
- Vận hành dùng dự báo nhu cầu để điều chỉnh tồn kho
Nếu Data Mining chỉ dừng ở báo cáo hoặc file phân tích, thì insight chỉ tồn tại trên giấy.
Hệ quả: dự án không tạo tác động thật, không thay đổi hành vi của đội ngũ, không cải thiện kết quả kinh doanh.
Data Mining (khai phá dữ liệu) không chỉ là phân tích dữ liệu mà là nền tảng giúp doanh nghiệp xây năng lực quản trị theo data bằng cách biến dữ liệu thô thành insight và quyết định có giá trị. Khi được triển khai đúng quy trình và áp dụng phù hợp các kỹ thuật như phân loại, phân cụm, dự báo hay phát hiện bất thường, Data Mining có thể hỗ trợ doanh nghiệp giải quyết các bài toán trọng tâm về doanh thu – chi phí – rủi ro, từ tối ưu marketing, bán hàng, chăm sóc khách hàng đến vận hành và tài chính.
Data Mining là gì?
Data Mining (khai phá dữ liệu) là quá trình phân loại và tổ chức các tập dữ liệu lớn nhằm xác định các mẫu (patterns) và thiết lập các mối liên hệ (relationships) để hỗ trợ giải quyết vấn đề thông qua phân tích dữ liệu.








